The Presentation layer's role is to respond to all user needs for reporting, data analytics and front-end applications like visualization or dashboarding. The focus is to optimize read-access, as opposed to write-access. The challenge is to optimize read-access without knowing the exact data access pattern that will be triggered from users interactions.
In this post, I'll define the physical data model created for a Redshift DWH Cloud target platform. This implementation choice influences considerably the resulting physical data model.
Redshift
Redshift is a Massively parallel processing (MPP) Cloud-based database suited for BI and analytics needs running on top of commodity hardware based architectures available from AWS. Among its features, we can highlight Columnar storage, high compression data, execution of query compiled code. More info available here and I've also gathered details on a separate post covering key aspects influencing data modeling.
Physical Data model
BRD integration layer is highly normalized and this can penalize Redshift data access performance. So we should first de-normalize our model by merging descriptive tables (ex. user_*) and association ones (ex. review_similarto, work_title, ..) into their parent entity.
Looking at the physical data model of the integration layer's model (see below), we see it is a bit complex and not suited to any end-user.
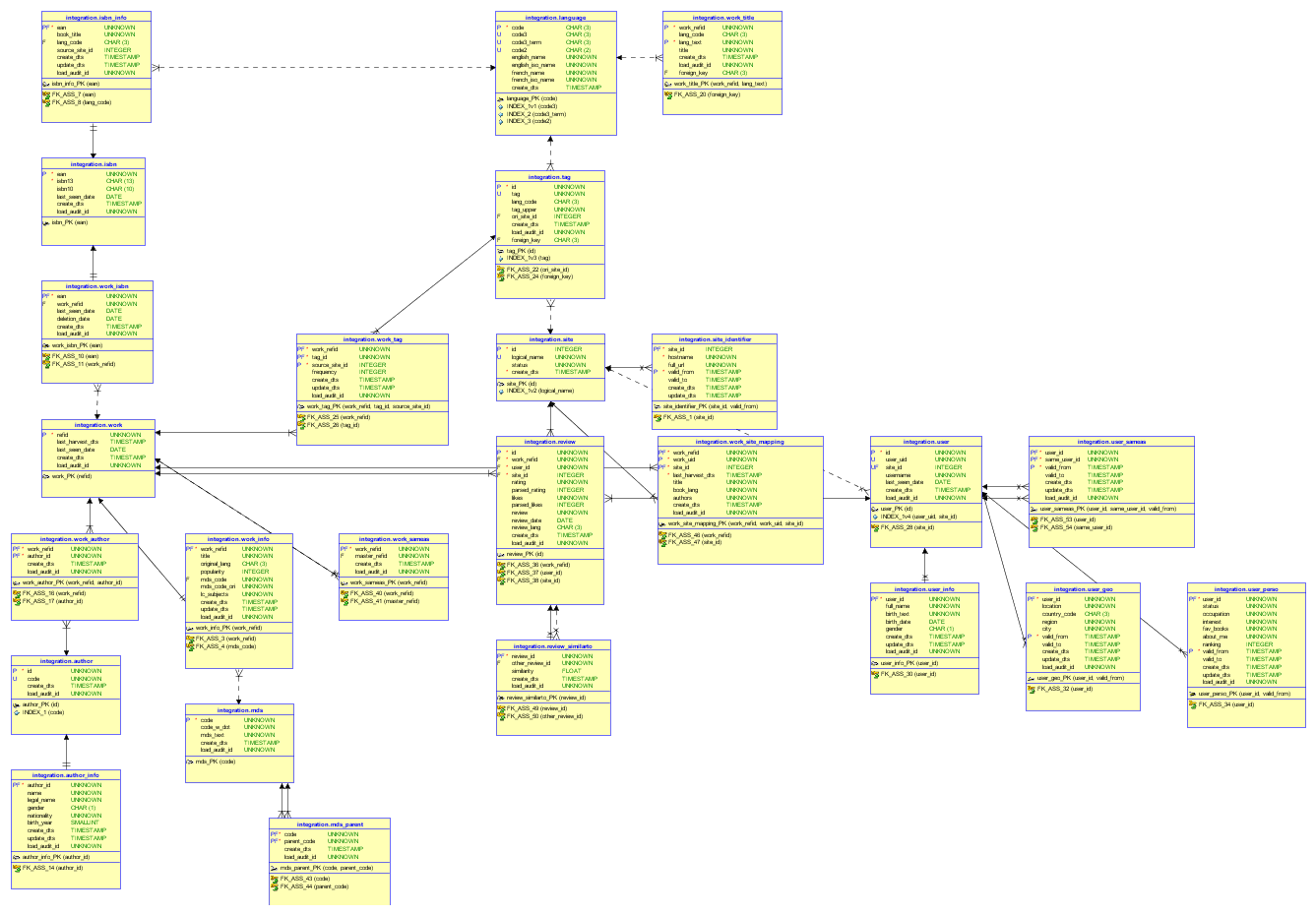
However Presentation layer should be easily interpreted and understood by a much larger audience, hence simpler. We have one central fact table REVIEW storing facts rating and nb_likes (and raw review text) for each review, surrounded by dimensions DIM_DATE, DIM_REVIEWER, DIM_BOOK and DIM_SITE. We also have tables REL_TAG and REL_AUTHOR capturing the more complex many-to-many relationship between a review and dimensions DIM_TAG and DIM_AUTHOR respectively.
Other changes required are due to Redshift support limitation of data type compared to Potgres. The TEXT type are converted to VARCHAR using data input to determine its size. Size is based on bytes and not character, hence to determine size required use SQL function octet_length() instead of char_length(). Also, UUID are replaced by BIGINT (note that UUID are useful for data integration where load can be parallelized without dependency on surrogate keys lookup, but not so useful for our Presentation layer).
For each table, we can also set Distribution type using assumptions on most frequent query joins, Sort key, as well as Compression encoding for all attributes.
The rest of this post discusses implementation details of some table.
Review
REVIEW table is by far our biggest table and needs to be distributed optimally. Its distribution key should correspond to one FK that often gets used for joining another large table. Two logical candidates are book_id for table BOOK or reviewer_id for table REVIEWER. At this point, it is quite difficult to know whether analysis of reviews will be mostly done against users demographic or book information. Without real usage audit, we can only guess... and that's ok, our layered-architecture approach offers the advantage of re-building this layer on demand (Integration-layer safely keeps our data)!
Let's assume book_id is the best candidate and co-locate reviews with their associated books data. As for sorting, we'll use review's date (DATE_ID) as a way to optimize time-series report.
create table presentation.review (
id bigint primary key,
id_similarto bigint,
-- dimensions
book_id int not null,
reviewer_id int not null,
site_id smallint not null,
date_id smallint not null,
-- facts
rating smallint,
nb_likes int,
lang_code char(3),
review varchar(30000), --based on max found
foreign key (book_id) references presentation.book(id),
foreign key (reviewer_id) references presentation.reviewer(id),
foreign key (site_id) references presentation.site(id),
foreign key (date_id) references presentation.dim_date(id),
foreign key (lang_code) references presentation.dim_language(code)
)
diststyle KEY distkey (book_id)
sortkey(date_id)
;
Tag
It is recommended to define character type as small as possible. We can determine the max size needed for the tag using a pre-loaded Postgres DB by:
select max(octet_length(tag)) from dim_tag;
The table TAG is relatively small (300K rows) and loaded in append-mode (inserting only), so we can safely set its Distribution style to ALL to offer best read performance:
create table presentation.dim_tag (
tag_id int primary key,
tag varchar(80) unique not null,
lang_code char(3) not null,
foreign key (lang_code) references presentation.dim_language(code)
)
diststyle ALL
;
Book
BOOK table holds informational data on Book reviewed. For reasons explained in REVIEW table, we chose id as distribution key. We also de-normalize different language titles pivoted by a few popular languages. This allows to do search query by title leveraging all cluster nodes.
We'll also sort rows along title_ori which should be used frequently as predicate.
create table presentation.dim_book (
id int primary key,
title_ori text,
ori_lang_code char(3),
mds_code varchar(30),
--pivot by popular lang
english_title varchar(500),
french_title varchar(500),
german_title varchar(500),
dutch_title varchar(500),
spanish_title varchar(500),
italian_title varchar(500),
japenese_title varchar(500),
swedish_title varchar(500),
finish_title varchar(500),
portuguese_title varchar(500)
)
diststyle KEY distkey (book_id)
sortkey(title_ori)
;
Reviewer
REVIEWER table holds informational data on users having reviewed one or more books. As with any dimension, its id is the attribute used in joins, so we'll use it for Distributing its rows. We decide to arbitrarily sort rows based on birth_year to favor queries filtering on this attribute.
create table presentation.dim_reviewer (
reviewer_id int primary key,
username varchar(200) not null,
gender char(1) not null,
birth_year smallint not null,
status varchar(20) not null,
occupation varchar(100),
city varchar(200) not null,
lati float,
longi float,
site_name varchar(20) not null
)
diststyle key distkey (id)
sortkey(birth_year)
;
Tuning parameters summary
The following table summarizes the choice of distribution style and sort key (not used at this point, but TODO later for optimization) for all tables.
| Table name | Sort key | Distribution style |
|---|---|---|
| Dim_author | name | ALL |
| Rel_author | n.a. | KEY (book_id) |
| Dim_book | note | KEY (book_id) |
| Dim_date | note | ALL |
| Dim_language | n.a. | ALL |
| Dim_mds | note | ALL |
| Dim_reviewer | note | KEY (reviewer_id) |
| Dim_site | n.a. | ALL |
| Dim_tag | note | ALL |
| Rel_tag | KEY (book_id) | |
| Review | note | by key (book_id) |
note: these would be set following realistic data access usage
Next step will be to populate it through Redshift load command and applying our business rules transformation logic. To be covered in a separate post.